

Anonymisering av känslig information

Anonymisering är en metod för att skydda personuppgifter och minska risken för integritetsintrång, särskilt i samband med databehandling och analys. Anonymisering innebär att personuppgifter bearbetas på ett sådant sätt att individer inte längre kan identifieras, varken direkt eller indirekt. När data är anonymiserat är det inte längre kopplat till någon specifik individ och anses därför inte vara personuppgifter enligt GDPR.
Det finns flera metoder för anonymisering, var och en med olika nivåer av säkerhet och komplexitet. Några av de vanligaste teknikerna:
- Aggregering – sammanställning av data på ett sätt som inte kan spåras tillbaka till enskilda individer. T.ex. genom att ett genomsnittsvärde ersätter aktuellt värde.
- Generalisation – dataelement ersätts med mer generella värden. T.ex. ett åldersintervall istället för exakt ålder.
- Data perturbation – tillförande av slumpmässigt brus till data för att förhindra identifiering av individer. Metoden förvränger de ursprungliga värdena men bevarar de övergripande mönstren och relationerna i data.
- Data masking – maskering av specifika dataelement för att dölja identifierbar information medan data fortfarande kan användas för analys.
- Top och bottom coding – ersättning av extrema värden med en viss gräns för att skydda individer med ovanligt höga eller låga värden.
- Synthetic data generation – skapande av artificiella data som behåller samma statistiska egenskaper som den ursprungliga datan, men inte innehåller några verkliga individer. T.ex. ett valitt personnummer som ersätter det ursprungliga.
Genom att välja och kombinera olika anonymiseringstekniker kan organisationer bättre skydda individers integritet samtidigt som de behåller användbarheten och kvaliteten på data för analys och beslutsfattande.
WiZITHIDE
WIZITHIDE kan anonymisera information både i transaktionsfiler eller direkt i källsystemens databaser. Metoden som används är en unik patenterad lösning som ger maximal flexibilitet i hur data anonymiseras. Flera av de ovan berörda metoderna kan kombineras för att säkerställa att känslig information skyddas enligt behov och önskemål.
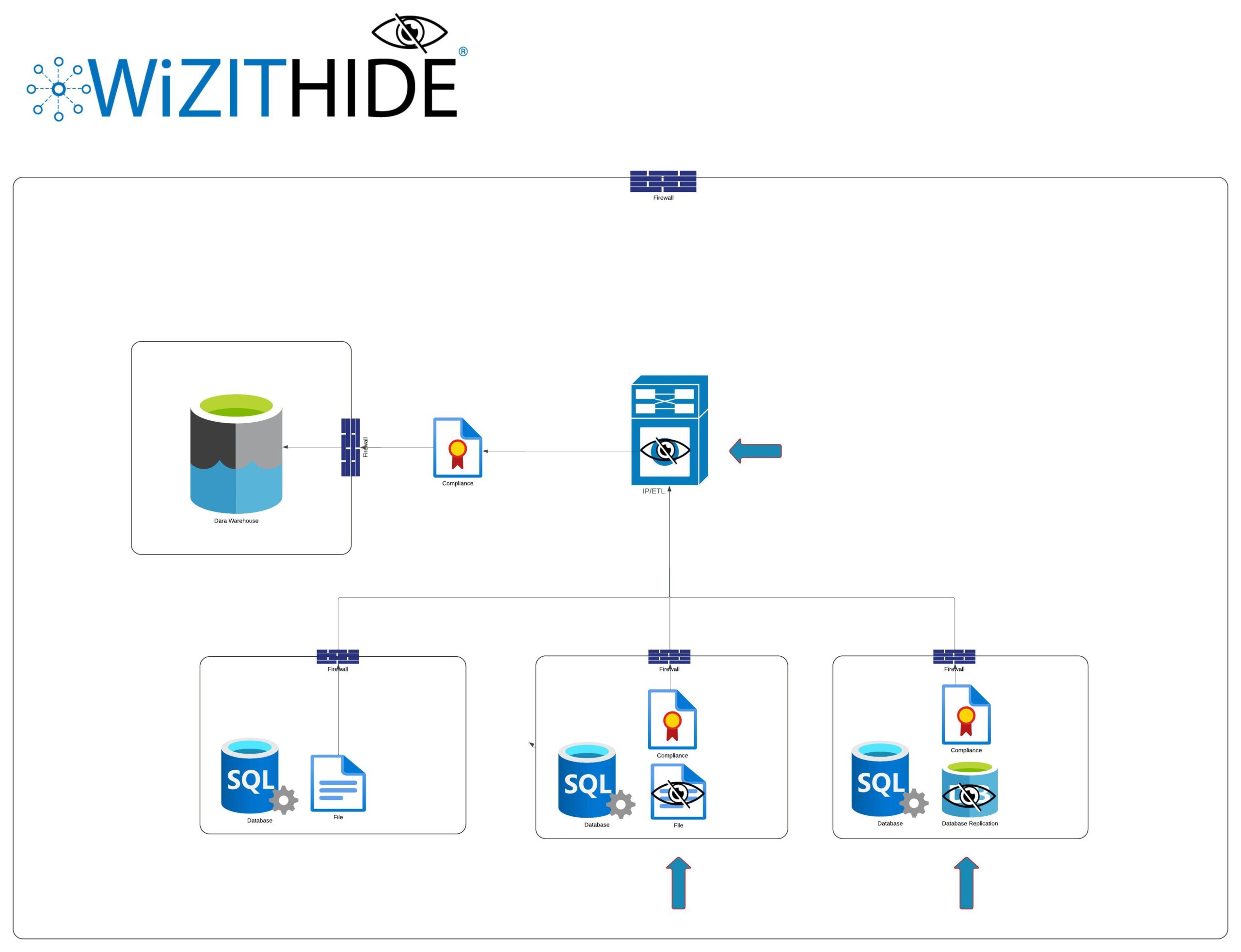
WiZITHIDE kan användas på olika sätt:
1. Som en komponent i en ETL-plattform eller i en integrationsplattform. WiZITHIDE exponeras som ett API som anropas från den aktuella plattformen.
2. Som lokal anonymiseringsmodul. Data extraheras från källsystemet och anonymiseras lokalt av WiZITHIDE innan överföring till datalager.
3. För anonymisering av databaser i källsystem. Aktuella delar av databas i källsystemet replikeras och anonymiseras av WiZITHIDE. Sedan extraheras information från den anonymiserade databasen och överförs till datalager.
Sammanfattat kan WiZITHIDE erbjuda en unik flexibilitet i kombination med maximal möjlighet till dataskydd. Logiken för att kombinera, styra och konfigurera anonymiseringsmetoder är patentskyddad av Avident IT och finns inte i någon annan produkt än WiZITHIDE.
